What is serverless and why should you use it
Serverless is a way of running application code only when there is actual work to do. Instead of keeping a service running all the time, a serverless platform starts your code when a request or event arrives and stops when the work is finished. That can reduce idle cost, scale more naturally for bursty traffic, and simplify operations for request-driven applications. It also changes tradeoffs around startup behavior, runtime limits, observability, and application design. To understand those tradeoffs, it helps to compare the older container-based model with the lighter-weight execution models many serverless platforms use today.
The dominant model: containers
Containers became popular because they made applications easier to package and deploy. Instead of manually configuring machines, developers could package an application with its dependencies and run it in a predictable environment. This made deployments more portable, repeatable, and easier to reason about. A container is usually a process running on a host operating system. It does not normally boot its own full operating system. Instead, it shares the host kernel and uses features like namespaces and cgroups to isolate the process and control resources. That model works extremely well for many systems. It is one of the reasons modern cloud development looks the way it does. But containers still behave like service-sized units. You start a container, the process begins, the application runtime loads, memory is allocated, and the service waits for traffic. Even when there is no work happening, the service still exists as a running process. That is a natural model for long-running services, but it is not always the most natural model for request-driven applications.
The emerging model: isolates
Serverless platforms move toward a smaller execution unit. Instead of thinking primarily in terms of long-running services, they think in terms of short-lived pieces of execution. A request arrives, code runs, and when the work is finished, the execution can disappear. One way platforms make this possible is through isolates. An isolate is a lightweight, sandboxed execution environment inside a shared runtime. The term is often associated with V8 isolates, but the broader idea is not limited to Chrome or JavaScript. WebAssembly runtimes can provide similar isolate-like execution through separate Wasm instances and isolated linear memory. Some platforms use microVMs, which are heavier than isolates but still part of the broader movement toward fast, demand-driven execution. The important idea is that isolates move the boundary inward. Containers isolate at the operating system and process level. Isolates isolate inside the runtime itself. That one difference is why they can be much cheaper to create.
Where the boundary lives
The real difference between containers and isolates is not just that one is “faster” than the other. The deeper difference is where the system draws the isolation boundary. In a container-based model, each unit of execution is a process. The operating system is responsible for enforcing the boundary around that process. In an isolate-based model, many execution units can live inside one already-running runtime process. Each isolate gets its own memory space or heap, but the runtime itself is shared. Here is a simplified view: 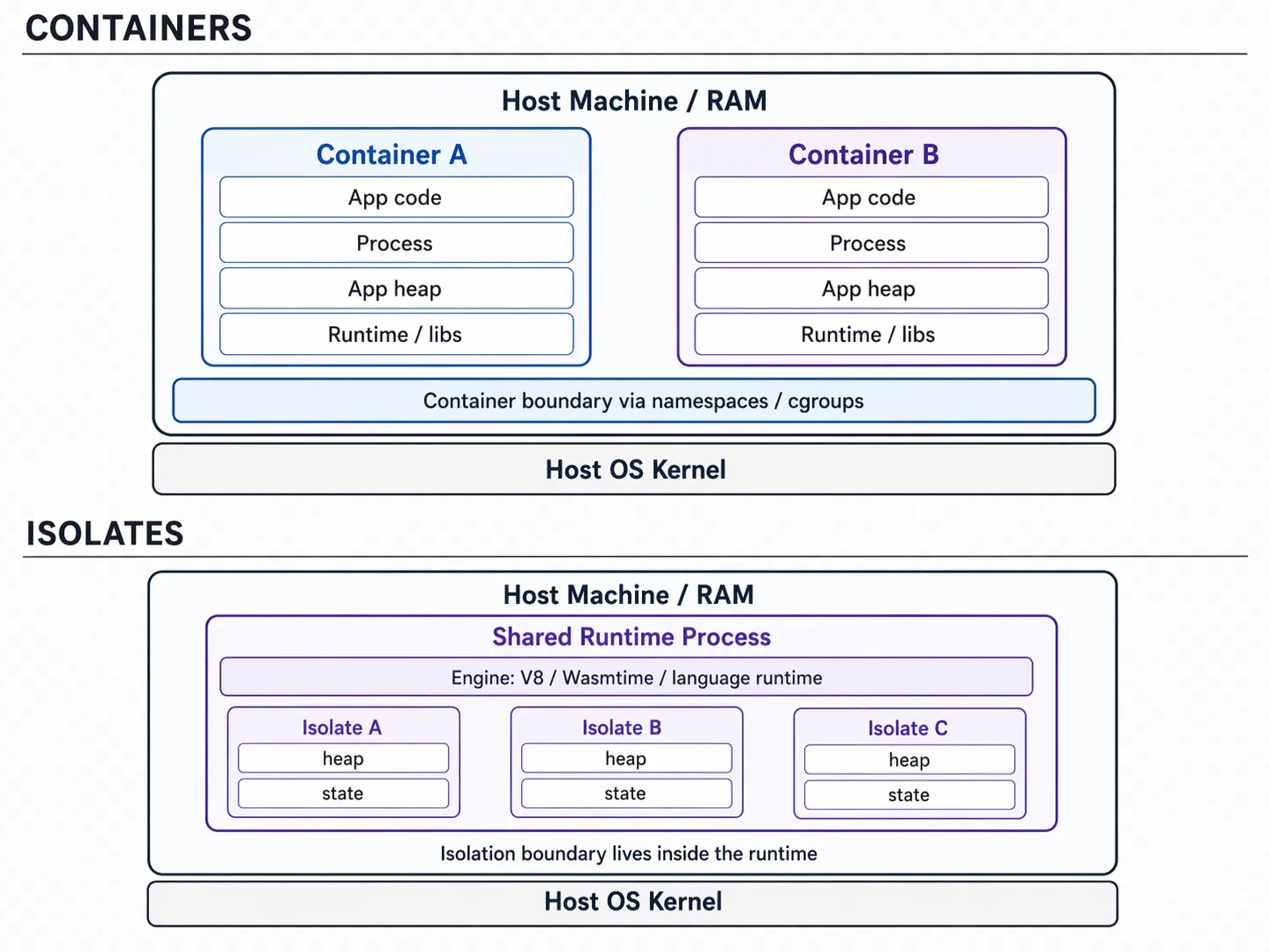 This diagram shows the heart of the difference. With containers, each unit carries its own process, runtime, heap, and application state. With isolates, the runtime is already running, and each new unit mostly needs its own isolated heap and execution context. Containers create another running environment. Isolates create another execution context. That is why the startup behavior is so different.
This diagram shows the heart of the difference. With containers, each unit carries its own process, runtime, heap, and application state. With isolates, the runtime is already running, and each new unit mostly needs its own isolated heap and execution context. Containers create another running environment. Isolates create another execution context. That is why the startup behavior is so different.
Why startup time matters
Startup time matters because it determines how small each request-sized piece of work can be. When a container starts cold, the platform may need to create the container’s isolation layer, start a process, initialize the language runtime, load the application code, allocate memory, and prepare the service to receive traffic. Even when this is optimized heavily, there is still meaningful work involved. An isolate has a smaller startup path. The runtime process is already alive. The engine is already initialized. The platform can create a new isolate, attach code or use cached compiled code, create its own memory space, and begin running it. That does not mean isolates have no startup cost. They do. But the cost is smaller because less has to be created from scratch. The key idea is simple: containers start whole running environments, while isolates start smaller pieces of work inside an already-running runtime. That difference is what makes serverless feel fast.
What makes serverless powerful?
Serverless becomes powerful when execution units are cheap enough to create on demand. If starting a unit of execution is expensive, you need to keep it running. That is the container model. You keep services alive so they are ready when traffic arrives. If starting a unit of execution is cheap, you can create it when work arrives. That is the serverless model. The platform does not need to keep every possible execution running ahead of time. It can react to demand. This changes how scaling works. In a traditional service model, you scale by adding more running services. In a serverless model, you scale by running more executions. The application does not need to be fully alive all the time. It only needs to run when there is something useful to do. That is why serverless feels like a more natural fit for request-driven applications. Traffic arrives in bursts. User activity changes throughout the day. Background jobs come and go. Most systems do not need every part of the application running at full capacity all the time. Serverless uses computing resources more in line with actual demand.
The cost model shift
The cost difference comes from the same place. With containers, you often pay for provisioned capacity. Even if your service is idle, the process is still running somewhere. It is still using memory. It may still reserve CPU. It still needs to be deployed, monitored, and scaled. With serverless, the ideal model is closer to paying for execution. Code runs when work exists. When there is no work, there is little or nothing to run. A simple way to say it is: you stop paying for waiting. That is not always perfectly true in every platform or every workload, but it captures the direction of the model. Serverless reduces the amount of infrastructure that exists only to be ready for future traffic. This is especially powerful for applications with uneven demand. A service that receives traffic only occasionally may still require a running container in a traditional model. In a serverless model, that same work can often be handled only when a request arrives. The result is not just lower cost. It is a different relationship between software and infrastructure. The infrastructure becomes more like a runtime.
Why has serverless not taken over everything?
If serverless is so powerful, it is fair to ask why every application is not already built this way. The answer is that serverless solves one set of problems while exposing another. The first challenge is state. Running a short-lived function is easy. Building a real distributed application usually requires durable state, coordination, ordering, retries, and observability. Those concerns do not disappear just because the compute layer is serverless. The second challenge is portability. Each serverless platform has its own runtime model, APIs, deployment format, and operational assumptions. Code written for one provider is often not easy to move to another. This makes developers cautious, especially when the platform becomes deeply tied to application behavior. The third challenge is tooling. Containers have a mature local development story. Developers understand how to build, run, debug, and deploy them. Serverless development is improving, but it can still feel fragmented across vendors and platforms. There is also a security tradeoff. Containers rely on operating-system and process-level isolation. Isolates rely more heavily on runtime-enforced isolation. That does not make isolates insecure, but it does move the trust boundary. The platform must trust the runtime to enforce memory separation and sandboxing correctly. These challenges are real. But they do not erase the power of the model. They show where the next layer of abstraction needs to emerge.
What should we expect to happen?
The trend is clear: execution units are getting smaller. We moved from physical machines to virtual machines. We moved from virtual machines to containers. Now serverless platforms are moving us toward isolates, Wasm instances, microVMs, and other lightweight execution models. Each step makes compute more flexible. Each step reduces the cost of starting work. Each step moves developers a little further away from managing infrastructure directly. The next question is not only how we deploy code. The next question is how we express distributed systems when the platform can create execution units on demand. If compute becomes cheap, fast, and portable, then developers should not have to manually wire together every queue, retry, service boundary, deployment target, and runtime behavior. The system should understand more of the application’s intent. That is the direction Distang is exploring. Serverless shows that infrastructure can behave more like a runtime. Distlang asks what programming distributed systems could look like once we fully embrace that idea.